



LLMs don’t improve by themselves. Localization has seen this before
Now that i’ve been using LLMs and AI more intensively for the past 2–3 years, and now that i’ve had some time experimenting with LLMs in localization, there are things I have clearer, things I’m still figuring out, and other things that are very clear to me but not always to others. So when I find myself in those situations, I try to explain them.
And I try to explain them in a way that doesn’t sound defensive, because I’m really not agains AI. I’m genuinely interested in the technology. There are things about AI that I find simply mind-blowing, both professionally and personally.
For example, at work it helps me create style guides much faster, and at home… I even built a GPT that helps me with cooking recipes (and my family is quite happy about that!) Yesterday I made a parmesan risotto with garlic shrimp that turned out really good, all thanks to the GPT telling me step by step what to do, with the right ingredients and the exact grams for 4 people, because I’m terrible at calculating that myself.
Anyway, let’s go back to the topic before I drift too much.
Where I don’t see AI as something that valuable anymore is when we use it to “reinvent the wheel”. Bear with me, I’ll explain what I mean.
One of the things I hear the most is that LLMs will eventually get better, that they will learn the style from our style guides, that they will understand context better, and that the output will improve. I heard this again this week in a meeting where we were reviewing progress on this year’s OKRs.
And yes, that statement is correct. LLMs are improving, they hallucinate less, and the output is getting better.
But there is one important aspect that is often forgotten when we say things like that.
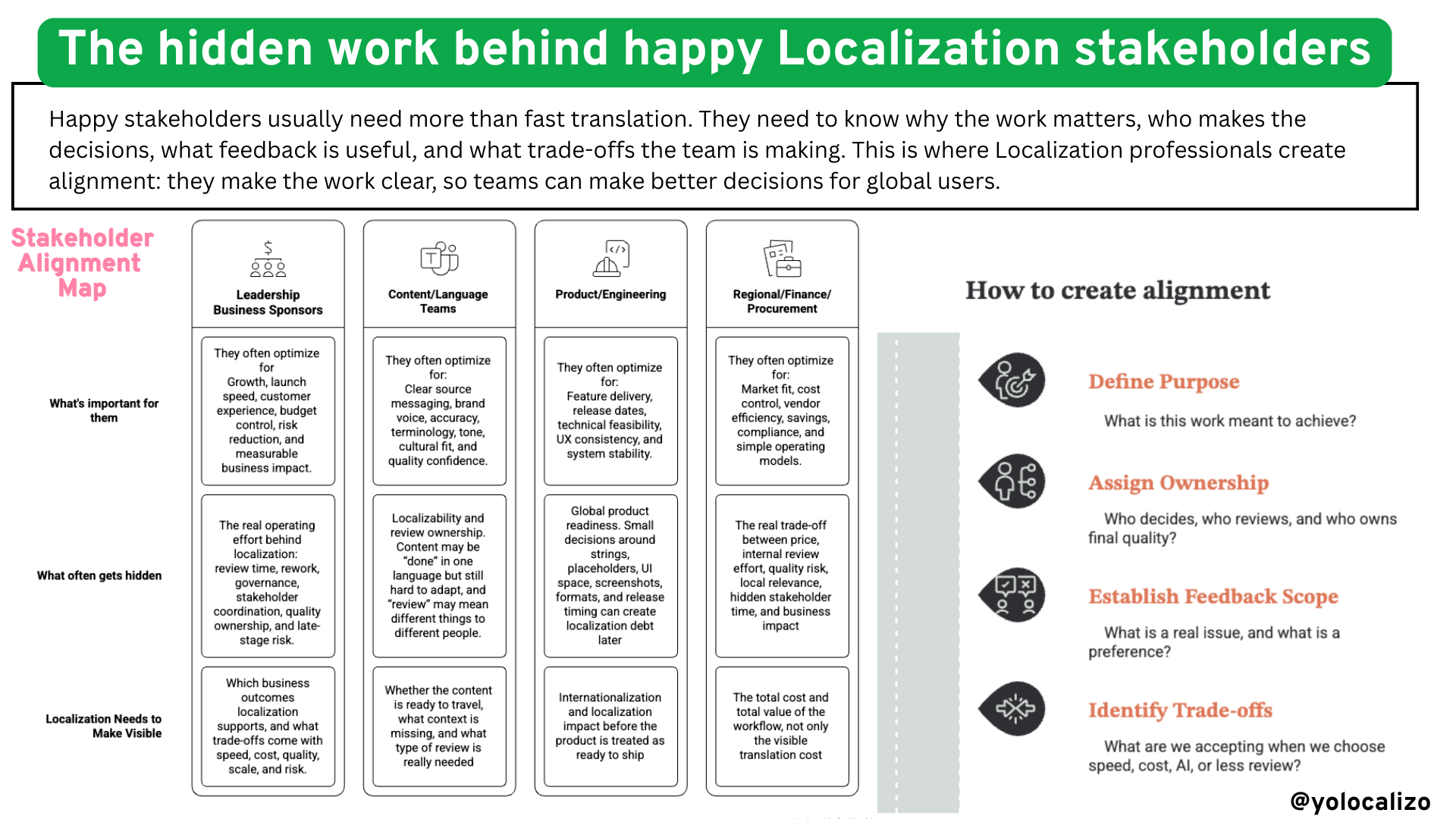
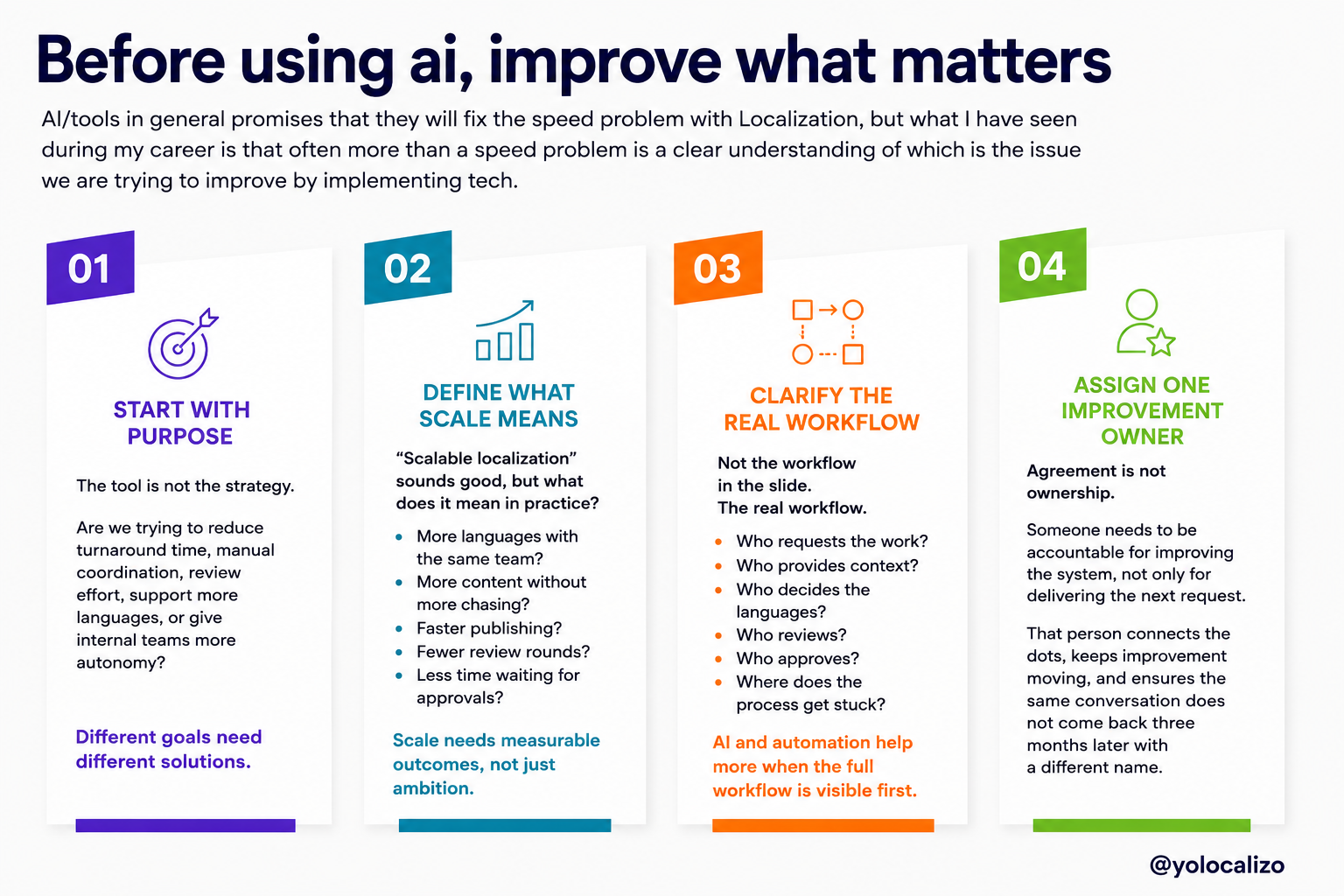
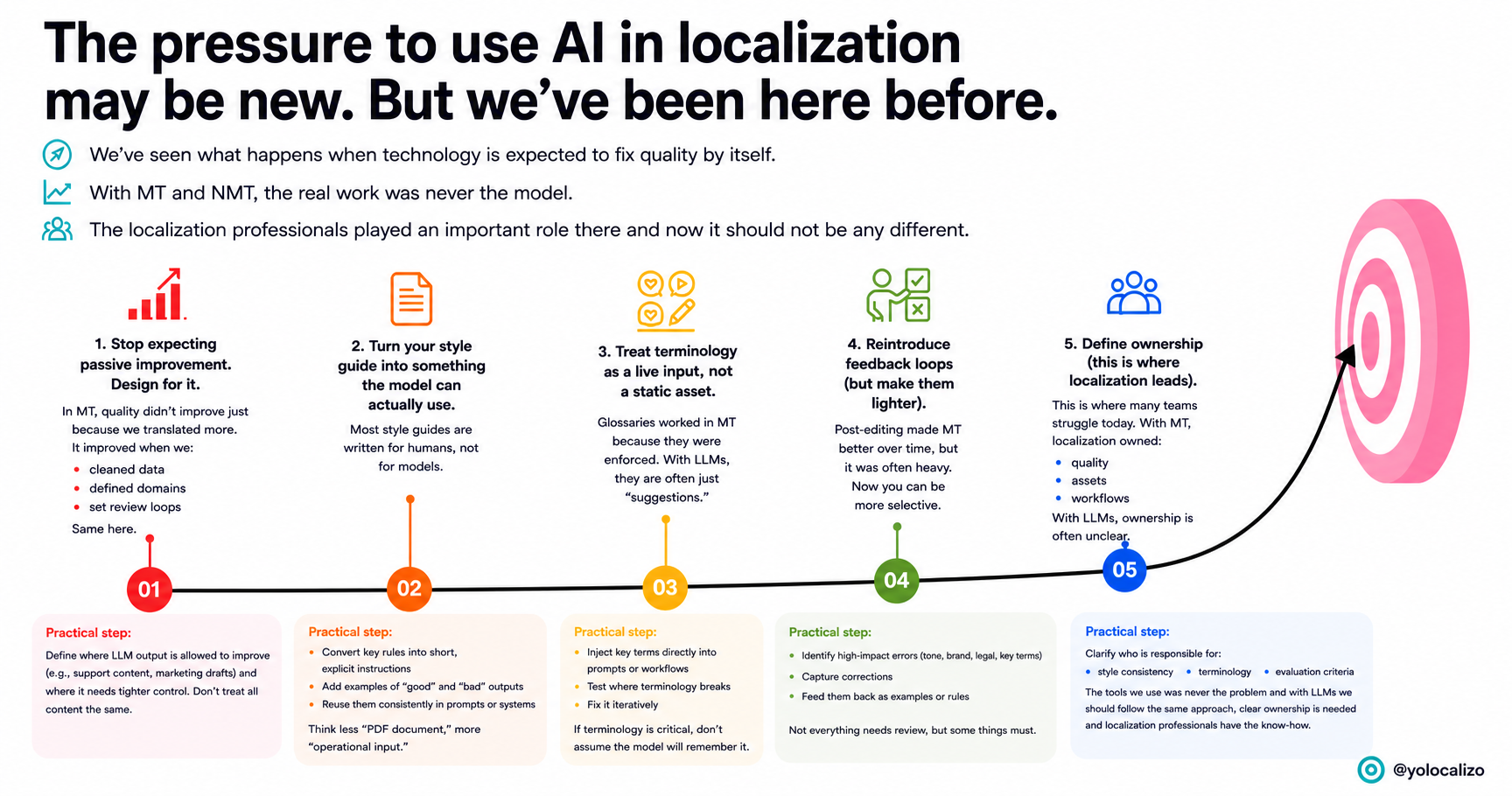
LLMs don’t learn on their own unless someone is actively feeding them with useful examples, correct terminology, and proper feedback loops. They don’t improve automatically, and definitely not by “magic.” Improvement is not passive. Someone needs to take care of it if we really want the model to learn the company’s brand style.
Learning is only one part of the challenge. If you’ve spent some time experimenting with LLMs in localization, you’ve probably noticed that consistency is not just an AI problem. Consistency is a system problem.
Let me connect this with what we already lived through with MT first, and later NMT.
One thing we learned when we started implementing NMT years ago is that NMT learns from data and feedback. It improved with more parallel data, better training, and post-editing feedback loops.
With LLMs, we are following a very similar path.
LLMs improve with prompts, examples, fine-tuning, RAG, and human corrections.
It’s a different technology, but it’s pretty much the same idea; quality comes from exposure and feedback.
If we continue with the parallels between what we faced before as localization professionals and what we are facing now, we can also look at style and terminology control.
Before, we controlled quality with assets inside localization tools: glossaries, translation memories, style guides, and QA checks.
Now, with LLMs, we need to bring those rules into the interaction itself through prompts, examples, system instructions, and terminology guidance.
So if you think about it, the goal hasn’t changed. We are still trying to reduce variability and keep consistency.
Another thing that feels like déjà vu is the expectation curve.
With MT, people also said: “it will get better over time.” And it did, but not magically. It improved where the data was clean, the domains were controlled, and the workflows were properly designed.
LLMs are following the same path. If those pieces are weak, the output will drift.
And one of the main problems I see today is that this idea of “it will get better” can hide a lack of ownership.
We already saw this during MT adoption.
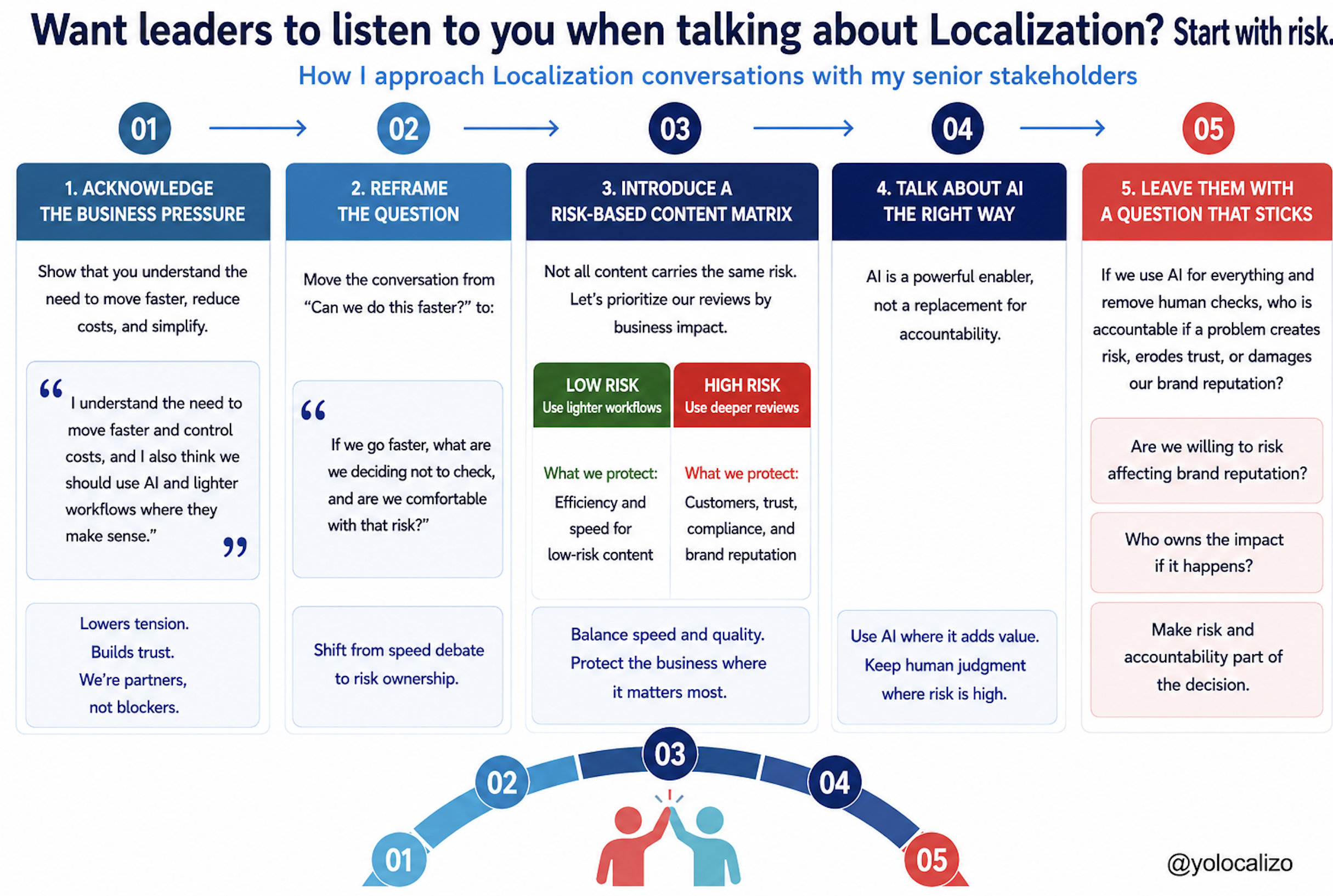
If a stakeholder waits for the model to fix quality on its own, the output may look good at first, but inconsistencies in tone, terminology, and workflow will surface later as rework.
And in the mid-term, who is taking care of the deterioration of the assets we are localizing across languages and content types?
That’s one of the false expectations I see today. There are layoffs in the industry, there is a lot of oversimplification of the problem, and what I’ve seen throughout my career using technology in localization is that quality doesn't improve just because we keep using the model. It improves when we build the right system around it.
Final Thoughts
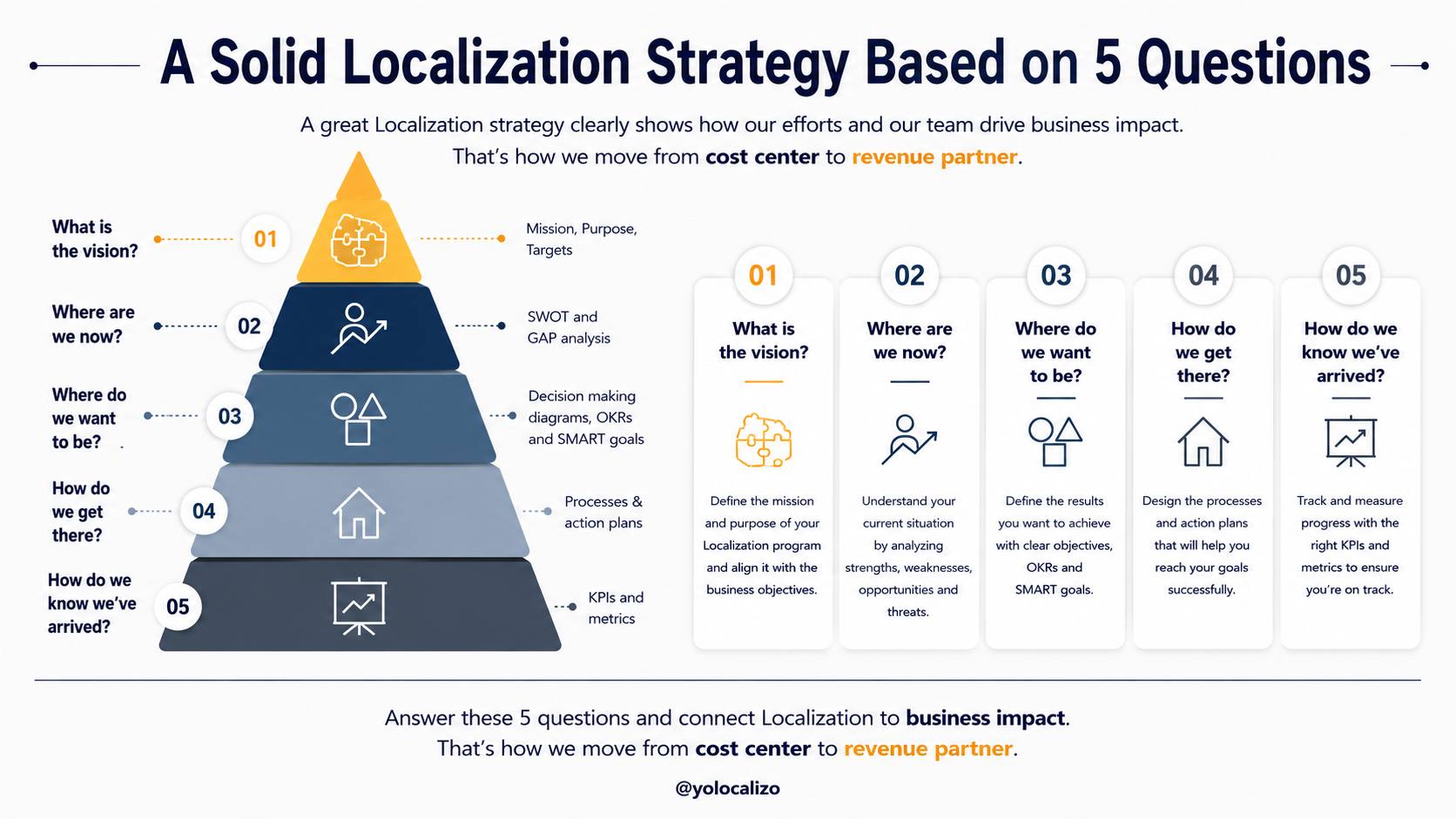
The AI conversation may feel new to many teams, but localization professionals have already lived through a version of it with MT and NMT. We know that quality does not improve just because a tool exists. It improves when people build the right assets, workflows, feedback loops, and governance around it.
That’s why localization should not just be invited to react to AI. Localization can help lead it.
And how do we help with that?
I hope this infographic I created can contribute to that 🙂
Click HERE to download the infographic
@yolocalizo
What if asking AI the same question in English, Hindi, or Arabic leads to different levels of critical feedback? Anthropic’s latest research raises fascinating questions about culture, AI behavior, and why Localization expertise may become increasingly relevant beyond translation.