






Defining a linguistic quality and review process - no more subjective changes
Back to my high school days Philosophy class and especially texts analysis were my nemesis. I still remember long discussions with my teacher, Claudio (btw, I think that's s a very appropriate name for being a philosophy teacher). The reason why we were clashing so often it was that the interpretation of philosophy texts was highly personal, quite often very subjective, and in my opinion philosophy comes with different angles and different points of views. I felt unfair that my grades depended on subjective aspects, it was his perception against my perception, it was very frustrating ….
In the G-localization industry, there’s a situation that it remembers me my old days in the school.
When someone emails me or tell me that “this translation sounds weird” I feel like I’m back to my philosophy classes, Weird?? What’s the real meaning of weird, if there’s not a grammar mistake, typo or any other type of mistake .. why is it weird? It’s very subjective feedback, is as subjective as my interpretation of “The allegory of the cave” from Plato vs the interpretation of my teacher.
Fortunately today, in our industry we are not as helpless as I felt when discussing with philosophy teacher. Today we have models of quality control and different workflows that help us answer someone when they let us know that "this translation sounds weird"
In this post, I want to share some ideas that it might help you to establish a linguistic quality program. Hopefully, the result of this program can help to challenge back those doubting without a clear reason about the quality of a translation we are providing…
The idea of having a linguistic quality control program responds to the following needs
- We don’t know how good or bad is the linguistic quality of the translations we receive
- We have many data but we are not sure what to do with them
- We have inconsistencies in our glossaries or TM and we want a way to minimize the pain the inconsistencies cause in our software
- We want to have strong metrics so the next time someone tells us “this translation sounds weird” (if this feedback is totally preferential and subjective) we regurgitate all the metrics we track, we share all the scoreboard we use, and we explain the quality assurance program we have in our organization The goal is not to end up in an exchanged of preferential thoughts (as I did with my teacher Claudio). Preferential changes lead to confusion. And after all without data, we are just another person with an opinion
Now the question is … how do we create this program?
Click HERE to download the infographic with a summary of the steps

Step 1 - Definition phase
- Define style guides
- Define glossaries
- Define process to answer translators questions
- Define error types, categories, and severities (Use a model, if it’s a recognized standard even better. For example DQF, the SAE J2450 QA Model or LISA, although LISA is al title bit obsolete nowadays.)
- Define scoreboard
- Define team of reviewers (another vendor, in-country resources, internal company resources)
- Assign a dedicated PM
In this phase, the key is to ensure everyone is aligned about what it should be included in the style guides, glossaries, and the workflow process to answer queries. If this part is not clear it’ll be really difficult for our vendors to meet our expectations.
Step 2 - Consolidate expectations! how good quality will look like. Review phase
- Review it- Proofreading, validation phase with the resources defined in the previous step
- Review master language content - We know that all saying, “garbage in, garbage out”. If our source language is English and it has poor quality chances are that target versions have also poor quality.
- Set feedback expectations. Every time we receive a change there’s need to be a reason why the change is suggested. This is the only way to escape from the vague feedback of “This translation sounds weird”
In this phase, the key is to align expectations about which is our definition of quality.
Step 3 - Consensus and Track it phase
- Give feedback to the translators about the quality.
- Share the scoreboard with the translators/vendors. Find a consensus to agree/disagree about the bugs reported. This will help to improve overtime collaboration
In this phase, the key is that scoreboard is reviewed by the translators. If they agree with the errors they made the changes and update the glossaries and translation memories so we can achieve the required consistency. If we don’t agree we’ll need a “judge” a third party or internal resources who makes a decision about what to do.
Step 4 - Verify
- Dev/Engineering teams create a build with the updated text files
- QA tester or a reviewer validates that the changes done in glossaries and TMs are actually implemented in the latest build.
One of the greatest challenges of anyone working as responsible for quality in the localization industry is managing quality for a wide range of different languages and different subject matters. The importance of an objective translation evaluation process is crucial to the success of a multilingual product. And this process needs to be objective it cannot be based on subjective interpretations. Subjective interpretations will lead to unfruitful discussions, like the ones I had with my philosophy teacher back in my youth...


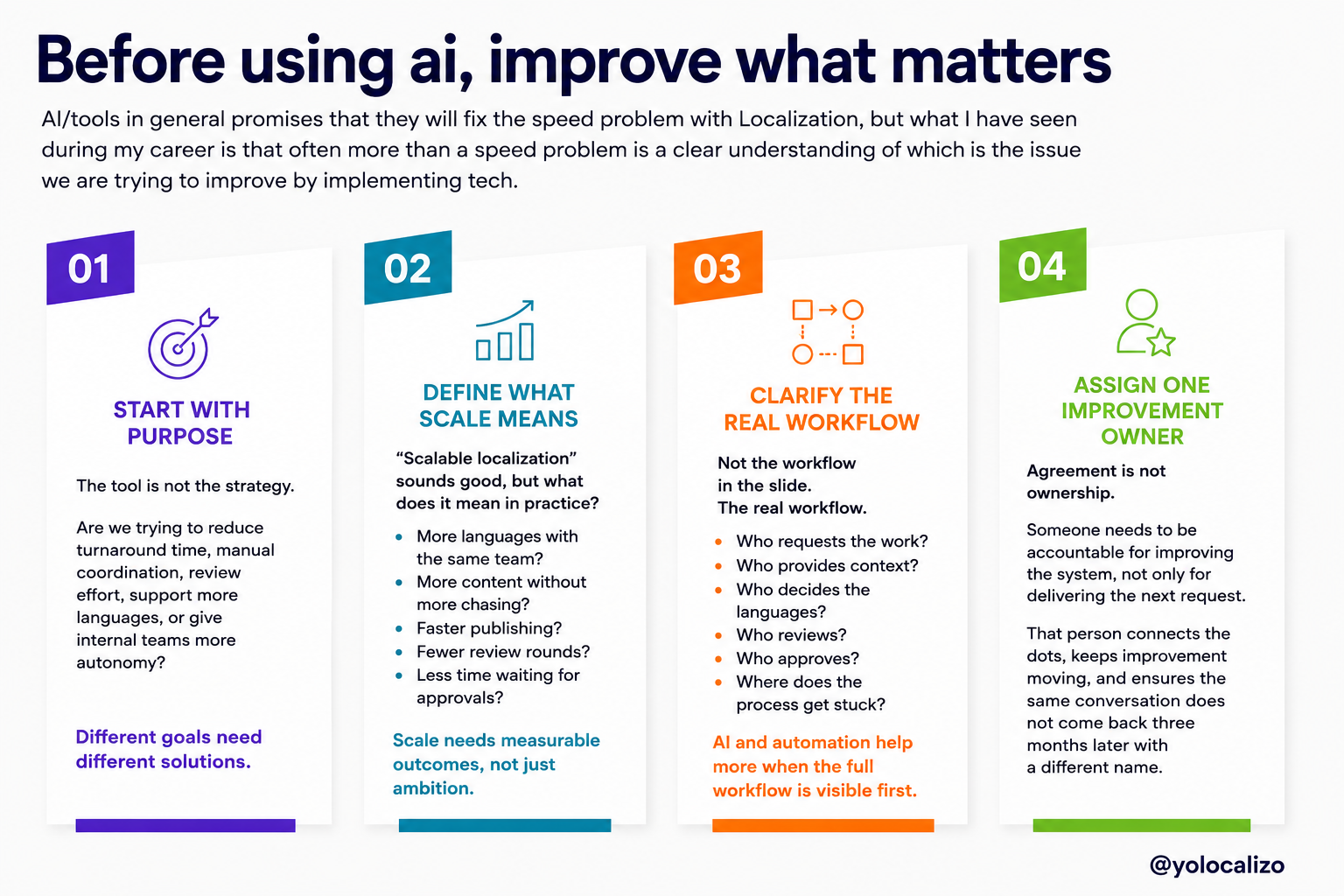
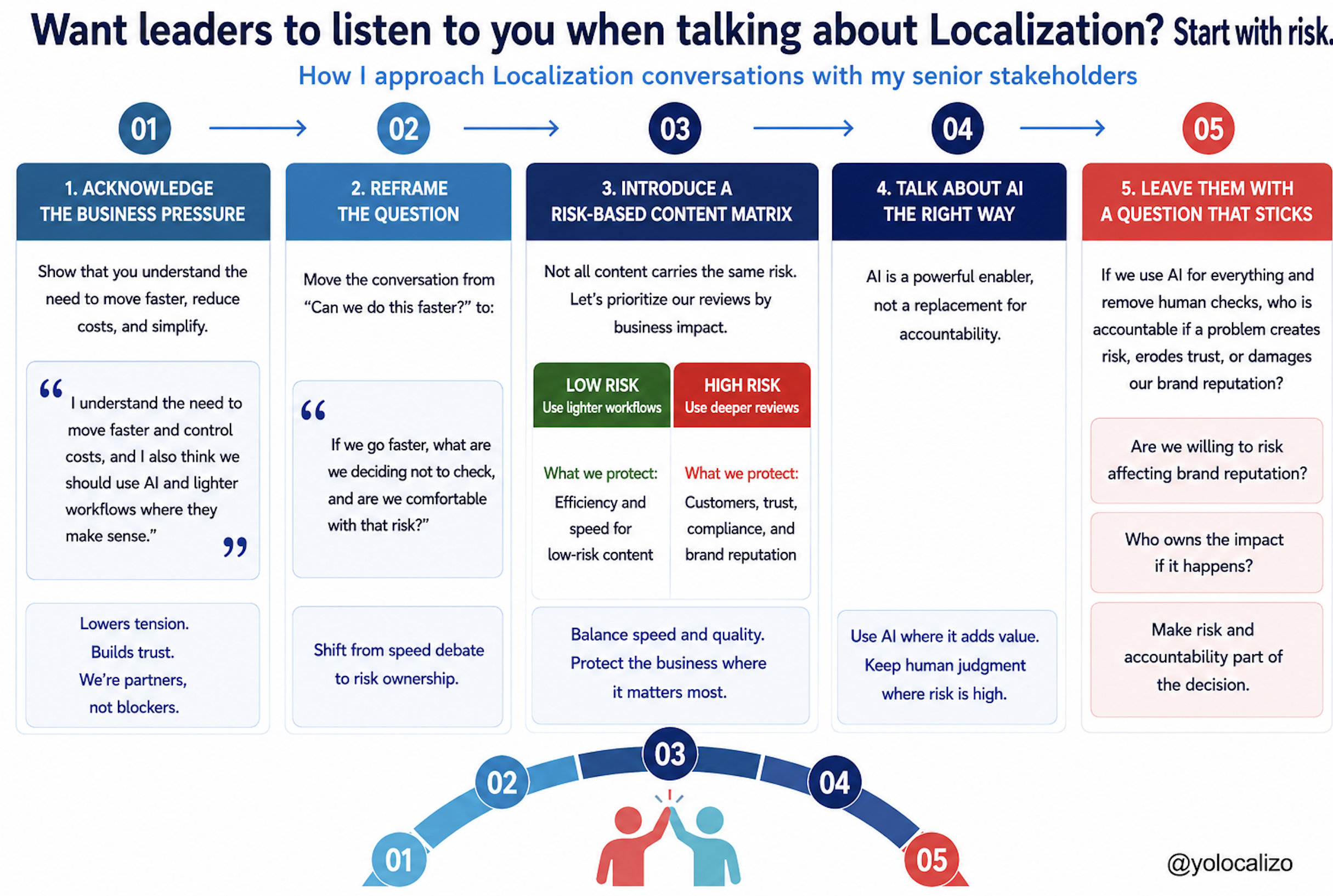
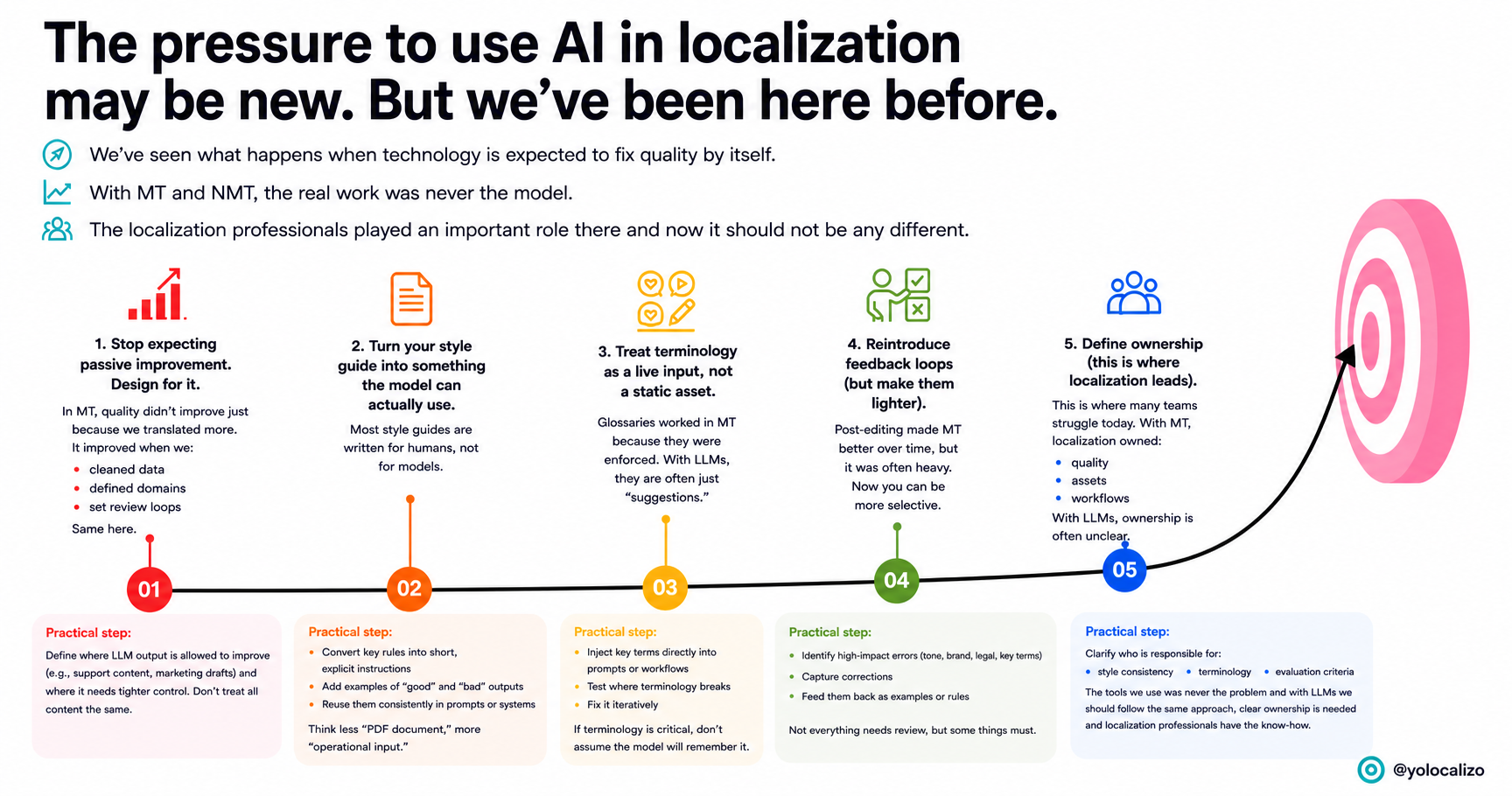
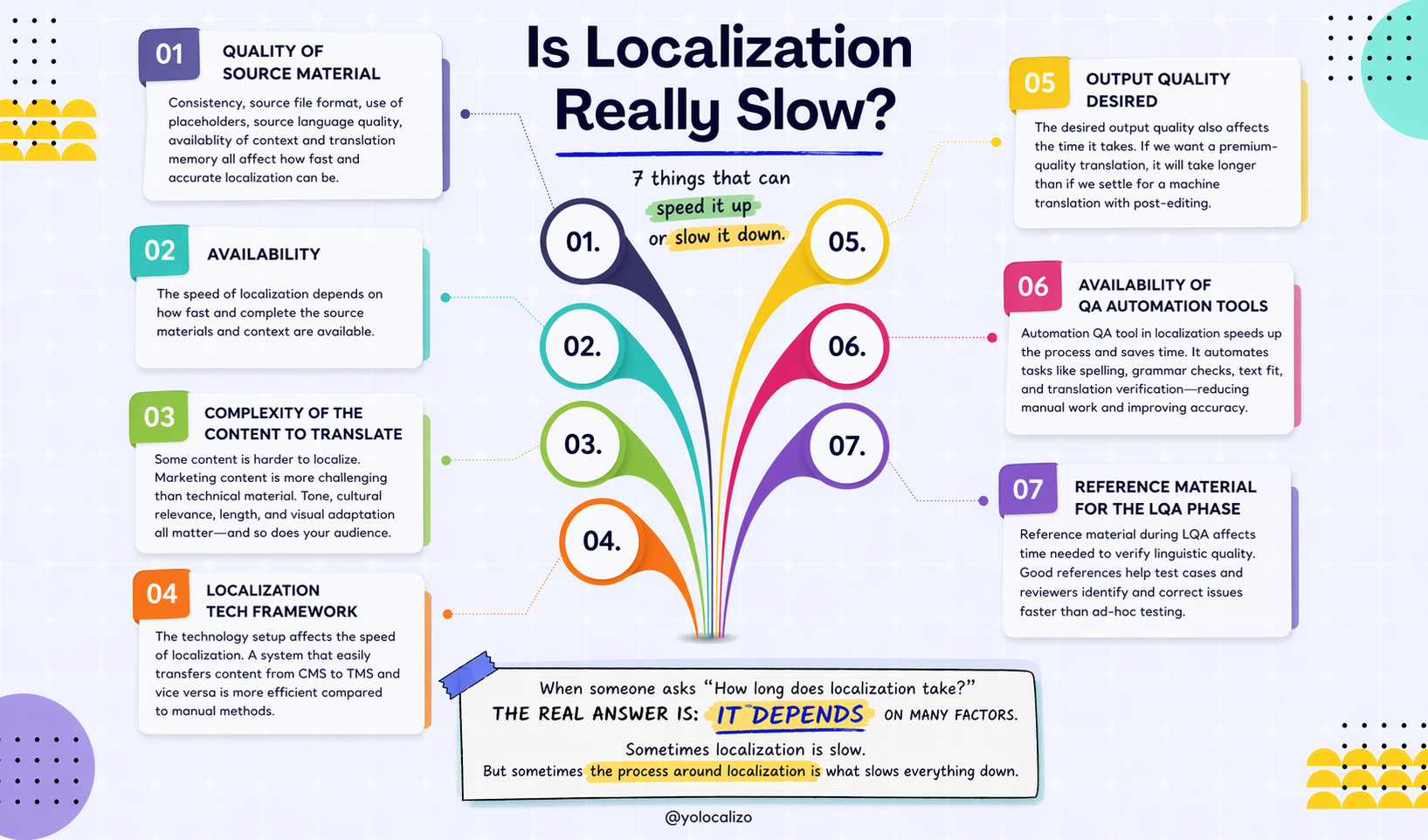
June is strategy season for many corporate teams. And for Localization, this usually means uncomfortable questions about budget, AI, workflows, markets, metrics, and business value. Before jumping into new tools or complex plans, maybe it is worth going back to the basics